

ID : MRU_ 435652 | Date : Dec, 2025 | Pages : 249 | Region : Global | Publisher : MRU
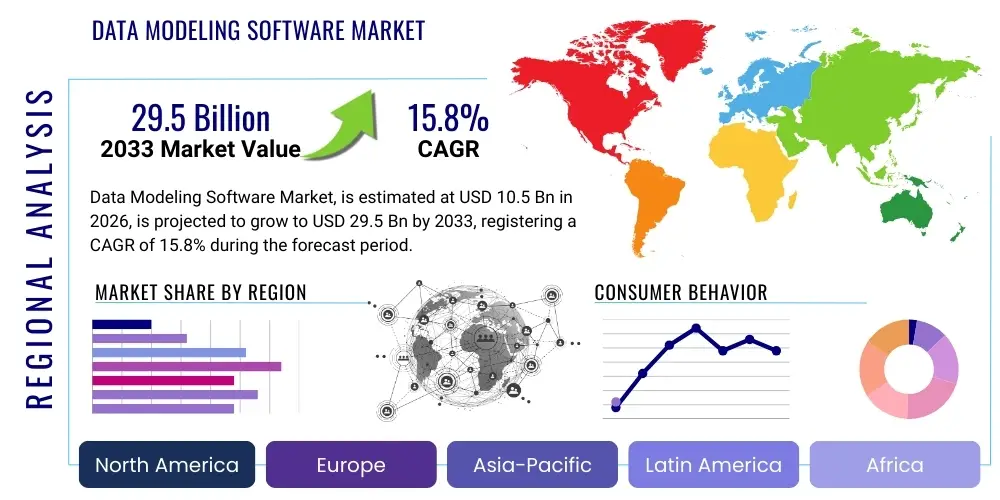
The Data Modeling Software Market is projected to grow at a Compound Annual Growth Rate (CAGR) of 15.8% between 2026 and 2033. The market is estimated at $10.5 Billion in 2026 and is projected to reach $29.5 Billion by the end of the forecast period in 2033.
The Data Modeling Software Market encompasses sophisticated tools designed to create, maintain, and document data models, which serve as blueprints for organizing and managing an organization’s data assets. These solutions translate complex business requirements into clear, graphical representations of data structures (conceptual, logical, and physical models), ensuring consistency, accuracy, and efficiency across disparate data storage systems. The core product provides functionalities such as reverse engineering existing databases, forward engineering models into schemas, synchronization capabilities, and comprehensive metadata management. Data modeling is fundamental to successful data warehouse implementation, migration to cloud platforms, and maintaining robust data governance frameworks necessary for regulatory compliance.
Major applications of this software span across enterprise architecture management, business intelligence (BI), master data management (MDM), and advanced analytics initiatives. By providing a unified view of data lineage and relationships, data modeling tools mitigate risks associated with data redundancy, improve data quality, and significantly reduce the time and cost involved in database development and maintenance. Furthermore, these tools are increasingly pivotal in facilitating modern data architectures, including data lakes, lakehouses, and highly distributed microservices environments, demanding semantic consistency across heterogeneous data sources.
Driving factors for market expansion include the exponential growth of big data volumes, the accelerated migration of mission-critical systems to cloud environments (IaaS and PaaS), and the stringent requirements for global data privacy and compliance standards such as GDPR and CCPA. Enterprises require scalable, reliable, and well-documented data infrastructure to harness advanced technologies like machine learning and artificial intelligence, thereby elevating the strategic importance of high-quality data modeling practices and the supporting software ecosystem.
The Data Modeling Software Market is currently characterized by significant convergence between traditional relational modeling techniques and capabilities tailored for NoSQL, graph, and streaming data architectures. Key business trends indicate a strong shift towards Cloud-Native Data Modeling (CNDM) solutions that offer enhanced collaboration, version control, and seamless integration with major hyperscale cloud providers (AWS, Azure, GCP). The competitive landscape sees established players focusing on integrating AI/ML features for automated schema inference and documentation, while agile startups prioritize tools optimized specifically for emerging data types and DataOps workflows, emphasizing speed and integration over sheer complexity. Enterprises are increasingly adopting subscription-based Software-as-a-Service (SaaS) models for flexibility and reduced initial capital expenditure.
Regionally, North America continues to dominate the market share, driven by high technological maturity, the presence of major tech innovators, and early adoption of advanced data architectures in the BFSI (Banking, Financial Services, and Insurance) and IT sectors. However, the Asia Pacific (APAC) region is projected to exhibit the highest Compound Annual Growth Rate (CAGR), fueled by massive digital transformation initiatives in countries like India and China, coupled with increasing governmental investments in cloud infrastructure and smart city projects. Europe maintains steady growth, largely spurred by mandatory data governance requirements stemming from EU regulations.
Segment trends highlight the rapidly increasing demand for tools capable of handling non-relational data modeling, reflecting the widespread adoption of technologies like MongoDB, Cassandra, and Neo4j. Furthermore, the Services segment, comprising consulting, implementation, and training, is experiencing robust growth as organizations require specialized expertise to integrate complex modeling tools into large-scale, heterogeneous data environments. From an end-user perspective, the Banking and Telecommunications industries remain leading consumers due to their critical need for robust customer data management and regulatory reporting, though the Healthcare sector is showing accelerated growth driven by genomics data and patient record standardization efforts.
Common user questions regarding AI's impact on data modeling software revolve primarily around automation, accuracy, and the changing role of the human data modeler. Users frequently ask if AI can completely automate the creation of physical data models from conceptual designs, how AI ensures semantic consistency across vast enterprise data estates, and whether AI-driven documentation tools are reliable enough for regulatory audits. Additionally, there is keen interest in how machine learning algorithms can be applied to optimize database performance by suggesting index strategies or partitioning schemes based on observed query patterns. The core concerns center on maintaining human oversight in complex modeling decisions and verifying the governance integrity of AI-generated models.
Based on this analysis, the key themes summarize the shift from manual, prescriptive modeling to augmented, adaptive modeling. Users expect AI to handle repetitive, low-level tasks such as schema generation, data type mapping, and initial documentation drafts, freeing human experts to focus on complex logical and conceptual architecture decisions. AI is anticipated to significantly reduce the time-to-model metric, especially in environments utilizing real-time data ingestion or rapidly changing source systems. Furthermore, AI capabilities are crucial for managing the sheer complexity of polyglot persistence (using multiple database technologies) by providing automated translation and synchronization layers between different modeling paradigms (e.g., relational models converted to graph models).
The immediate impact of AI is seen in enhancing tool efficacy rather than outright replacement of data modelers. AI algorithms assist in detecting anomalies in schema design, predicting data growth patterns to inform capacity planning, and generating synthetic data for testing model resilience. This augmentation ensures that data models remain relevant and performant even as underlying business requirements and data velocity increase, effectively transforming the data modeler's role into one of strategy, validation, and advanced governance oversight rather than manual diagramming and definition writing.
The market trajectory for Data Modeling Software is propelled primarily by the massive organizational imperative for digital transformation, necessitating a structured and governed approach to data assets. Drivers include the accelerating adoption of cloud data warehouses (Snowflake, Databricks) which require precise, often non-traditional, physical modeling, and the urgent need for data governance tools to manage large-scale data lakes effectively. Opportunities abound in integrating modeling software with DataOps and MLOps pipelines, enabling automated schema evolution and version control within continuous integration/continuous deployment (CI/CD) environments. Conversely, the market faces restraints such as the steep learning curve associated with highly complex enterprise modeling tools, the high initial licensing and customization costs for proprietary solutions, and persistent challenges in standardizing models across disparate legacy systems.
Driving forces center on regulatory pressures and the competitive need for data agility. Regulations like HIPAA and Basel III enforce rigorous standards for data quality and auditable lineage, making advanced modeling tools indispensable for compliance. Furthermore, organizations seeking competitive advantage through advanced analytics must ensure their foundational data models are scalable, reliable, and optimized for machine learning training datasets. The shift towards microservices architecture, requiring decentralized data management but centralized conceptual governance, is a significant driver necessitating sophisticated, collaborative modeling platforms that support architectural flexibility.
Impact forces dictate that vendors must prioritize usability and seamless integration. The intense demand for polyglot persistence—the ability to model relational, NoSQL, and graph databases simultaneously—is reshaping product development. Tools that offer robust visualization capabilities, automatic metadata harvesting, and low-code/no-code interface options for business users (abstracting technical complexity) will capture the largest market share. The continuous challenge of managing technical debt in legacy systems also represents a continuous service opportunity for vendors specializing in reverse engineering and modernization consulting services.
The Data Modeling Software market is segmented based on deployment mode, component type, data type, end-user industry, and organization size, reflecting the diverse needs of enterprises navigating complex data environments. The analysis reveals a clear transition toward subscription-based, cloud-deployed solutions, driven by scalability requirements and the desire for operational flexibility. While established relational data modeling tools continue to form the market base, the high growth segments are unequivocally those focused on non-relational and hybrid data modeling capabilities, addressing the explosion of unstructured and semi-structured data sources. Understanding these segment dynamics is crucial for vendors to tailor their offerings toward specific architectural shifts, such as the adoption of cloud data lakes and distributed ledger technologies.
The value chain for the Data Modeling Software market begins with the upstream activities of software development, focusing on core engine architecture, visual design interface development, and ensuring compatibility with emerging database technologies (e.g., Snowflake, CockroachDB). This stage involves heavy investment in R&D to incorporate advanced features like AI-driven automation, collaborative features, and deep integration with metadata management platforms. The distribution channel is bifurcated: direct sales channels involve vendors providing licenses and services directly to large enterprises, often including bespoke training and consulting. Indirect channels utilize system integrators (SIs), specialized IT consulting firms, and value-added resellers (VARs) who bundle the modeling software with broader data architecture implementation projects, providing crucial localized support and expertise.
Midstream activities involve implementation and integration services, a high-growth segment driven by the complexity of migrating legacy models to the cloud or integrating new modeling tools into existing DataOps pipelines. Professional services teams, whether in-house or third-party, customize the software to enterprise-specific standards, develop necessary scripts for synchronization, and ensure compliance with internal governance policies. The efficiency of this stage significantly impacts the time-to-value for the end customer, making robust training and well-documented API support essential components offered by the vendor.
Downstream, the value chain focuses on customer support, maintenance, and ongoing evolutionary services. As data models must constantly evolve to reflect changing business processes, continuous support services, often delivered through a SaaS subscription model, are critical. This stage also includes specialized consulting for advanced data architecture strategies (e.g., data mesh implementation), security audits related to data access defined by the models, and ensuring seamless upgrade paths. The strength of the vendor ecosystem, particularly the partnerships with cloud providers and major data infrastructure companies, determines the long-term perceived value and stickiness of the software in the enterprise environment.
Potential customers for Data Modeling Software are predominantly organizations operating in data-intensive sectors that require strict governance, high data quality, and complex relational or hybrid data architectures. The primary end-users or buyers include Chief Data Officers (CDOs), Enterprise Architects, Database Administrators (DBAs), Data Governance teams, and specialized Data Modelers within large enterprises. These customers prioritize tools that offer enterprise-level scalability, robust security features, and capabilities for managing both transactional and analytical data domains. Large organizations across regulated industries, such as financial services and healthcare, are compulsory buyers due to regulatory requirements necessitating auditable data lineage and precise data definition documentation.
Furthermore, mid-market companies undergoing rapid digital expansion or migrating substantial on-premise infrastructure to the cloud represent a fast-growing customer segment. For SMEs, the key purchasing criteria often shift towards affordability, ease of use, and the availability of cloud-based, subscription services that minimize internal IT overhead. These customers often seek integrated tools that can handle basic modeling requirements while offering straightforward connectivity to popular data visualization and ETL (Extract, Transform, Load) tools, facilitating faster time-to-market for new data products and analytical dashboards.
The customer base is diversifying to include development teams engaged in microservices architecture, who require tools that support schema definition for APIs and decentralized data stores, moving beyond traditional centralized data warehousing needs. Technology companies and software vendors themselves utilize these tools extensively during product development to ensure database optimization and seamless integration capabilities. Consequently, the focus is shifting from monolithic database design tools to collaborative platforms that facilitate communication and consensus among diverse stakeholders across the organization, from business analysts to DevOps engineers.
| Report Attributes | Report Details |
|---|---|
| Market Size in 2026 | $10.5 Billion |
| Market Forecast in 2033 | $29.5 Billion |
| Growth Rate | CAGR 15.8% |
| Historical Year | 2019 to 2024 |
| Base Year | 2025 |
| Forecast Year | 2026 - 2033 |
| DRO & Impact Forces |
|
| Segments Covered |
|
| Key Companies Covered | ER/Studio (IDERA), Erwin, Oracle, IBM, SAP, Quest Software, Microsoft, Micro Focus, Sparx Systems, Vertabelo, Navicat, Hackolade, DbSchema, Dataedo, Lucidchart, Xplenty, Talend, Informatica, Atlan, Collibra |
| Regions Covered | North America, Europe, Asia Pacific (APAC), Latin America, Middle East, and Africa (MEA) |
| Enquiry Before Buy | Have specific requirements? Send us your enquiry before purchase to get customized research options. Request For Enquiry Before Buy |
The technology landscape of the Data Modeling Software market is evolving rapidly, driven by the need for tools to manage increasingly complex and distributed data ecosystems. A central technological theme is the shift toward sophisticated metadata management systems integrated directly into the modeling environment. Modern tools are not just static diagramming utilities; they function as active metadata hubs that capture, catalog, and govern data definitions throughout the entire data lifecycle. Key innovations include the development of semantic layers that decouple business terms from physical database structures, allowing for greater organizational agility and enabling business users to understand data relationships without needing deep technical knowledge of schemas. Furthermore, API-first design principles are critical, ensuring the modeling software can interact seamlessly with automated DataOps tools and cloud resource provisioning services.
Polyglot persistence support represents another major technological requirement. Vendors are investing heavily in engines capable of modeling diverse data paradigms—from third normal form relational databases to document stores (JSON), key-value pairs, and graph databases. This includes visual mapping and transformation capabilities that allow modelers to derive a physical schema for one database type from a conceptual model optimized for another. For instance, creating a Cassandra keyspace design directly from an enterprise-level logical data model. This technological flexibility is non-negotiable for enterprises adopting distributed, microservices-based architectures where multiple specialized data stores are utilized simultaneously.
Finally, the integration of generative AI and machine learning techniques is fundamentally altering the technology stack. This includes features like automated database reverse engineering with higher accuracy, intelligent suggestions for normalization or denormalization based on predicted workload, and automated schema migration verification. Cloud-native architecture is also a prerequisite for new market entrants, providing collaborative real-time editing, robust version control inherent in the platform (like Git integration), and consumption-based pricing models. These features collectively enhance collaboration, ensure architectural consistency, and significantly accelerate the data architecture phase of large projects.
The primary driver is the pervasive adoption of cloud data platforms and the corresponding explosion of big data, which necessitates stringent data governance and documented, scalable data architectures to ensure compliance and reliable analytical outcomes.
AI is augmenting the data modeling process by automating tasks such as schema inference, generating comprehensive metadata and documentation, and suggesting performance optimizations, thereby allowing human data modelers to focus on high-level architectural strategy and validation.
The Non-Relational Data Modeling segment, which includes support for NoSQL, Graph, and document databases, is projected to exhibit the highest growth rate, driven by the increasing complexity of enterprise data requiring polyglot persistence solutions.
Cloud-based solutions offer superior advantages in scalability, reduced operational expenditure (OpEx), enhanced collaboration through real-time sharing, and seamless integration with major cloud provider data services, supporting modern DataOps and CI/CD pipelines efficiently.
Yes, data modeling software is critical for Data Lakes and Lakehouses to impose structure on unstructured data, define semantic consistency, and maintain data governance. It helps organize the raw data layer and ensures reliable transformation into consumption-ready structured formats.
Data Modeling Software serves as the foundational layer for data governance by providing accurate, consistent definitions, relationships, and auditable data lineage. It enforces naming standards and business rules across the enterprise, ensuring regulatory compliance and data quality.
In microservices, data is decentralized. Modeling tools support this by allowing developers to define schemas for individual microservice databases (polyglot persistence) while maintaining a high-level conceptual or logical model to ensure overall enterprise data consistency and integration feasibility.
Large enterprises should prioritize enterprise-level features such as robust version control, collaborative features, extensive support for heterogeneous database types (including legacy systems), advanced security protocols, and seamless integration with existing metadata management platforms and IT ecosystem tools.
The BFSI sector requires intensive data modeling due to the complexity of transactional data, strict requirements for financial regulatory reporting (e.g., Basel, Solvency II), and the critical need for accurate customer data management for fraud detection and risk assessment.
Conceptual models define the high-level business scope and entity relationships (business view). Logical models detail entities, attributes, and relationships regardless of the specific database platform (system view). Physical models specify the actual implementation details, including data types, indexes, and partitions for a target database technology (technical view).
Integration with DataOps enables automated schema evolution, continuous integration/continuous deployment (CI/CD) of database changes, and version control for data models, significantly reducing manual errors and accelerating the deployment lifecycle for data products and database updates.
The Asia Pacific (APAC) region is projected to register the fastest CAGR, driven by rapid digital transformation, increasing technological maturity, and large-scale public and private sector investments in cloud infrastructure and data analytics capabilities across countries like India and China.
Major restraints include the high total cost of ownership (TCO) for comprehensive enterprise licenses, the specialized skills required to operate advanced modeling platforms effectively, and the significant challenge of integrating new tools with deeply embedded, non-standardized legacy data environments.
The Services segment (consulting, implementation, and training) is highly significant because the complexity of modern data environments necessitates external expertise for successful deployment, customization, and integration of modeling tools with existing data governance and DataOps frameworks.
Vendors are increasingly developing cloud-native platforms that support real-time collaborative editing, granular permission controls, built-in communication features, and integration with source control systems (like Git) to facilitate teamwork among distributed data architecture teams.
Polyglot Persistence refers to the ability of data modeling software to support and visually represent schemas and relationships across multiple, disparate database technologies simultaneously (e.g., relational, NoSQL document stores, graph databases) within a unified enterprise model.
Data Modeling Software is essential for modernization projects as it allows organizations to reverse-engineer legacy schemas, refine the logical model, and forward-engineer an optimized physical model tailored for new cloud-native data warehouses, ensuring a smooth and accurate migration.
Metadata management is critically important, moving beyond documentation to becoming an active function. Modern tools act as metadata hubs, automatically capturing, cataloging, and governing business and technical metadata, ensuring the modeled relationships are consistently reflected across all connected data systems.
Opportunities exist in integrating modeling tools with advanced analytics platforms to design models specifically optimized for machine learning feature stores and high-performance querying, ensuring data scientists can access high-quality, governed data efficiently.
Open-source tools increase market accessibility for SMEs and startups, potentially driving down costs for basic functionality. However, proprietary tools remain dominant in large enterprises due to the need for advanced features, dedicated support, and specialized integrations with complex enterprise resource planning (ERP) systems and security infrastructure.
By enforcing clear definitions of sensitive data elements, tracking data lineage (who uses what data, where), and integrating security attributes directly into the model, these tools help organizations document and control data access, directly supporting compliance mandates like GDPR and CCPA.
Key innovations include seamless cloud-native deployment, API-first architectural design, deep integration of automated AI/ML services for model augmentation, and sophisticated semantic layer technology to bridge the gap between technical schemas and business terminology.
The increasing complexity of distributed systems (like event-driven and microservices architectures) actually boosts demand, as centralized, robust modeling is required to maintain conceptual consistency and prevent data silos across numerous decentralized data stores.
Data Modeling Software focuses on defining the structural architecture, integrity constraints, and relationships of data assets before they are implemented, whereas general data visualization tools primarily focus on displaying and analyzing the implemented data to extract business insights.
The IT and Telecommunications sector is a major consumer due to its massive subscriber data volumes, complex billing systems, and continuous need for infrastructure scalability and service reliability, all of which require meticulous data modeling for optimization and management.
The demand for services is growing faster than pure tool sales, shifting towards specialized consulting in cloud migration, DataOps pipeline integration, and architecting modern data mesh frameworks, requiring expertise beyond basic software usage.
Modern tools allow logical models to be database-agnostic, focusing on concepts and relationships. Physical modeling then translates this logical structure into specific, optimized code (DDL) for a chosen database platform, including physical implementation details like indexing and storage parameters.
Version control is critical for tracking changes, managing model evolution over time, allowing for rollbacks to previous stable states, and enabling collaborative work environments, ensuring that all teams are working against the approved and current data blueprint.
Database connectors are essential as they facilitate reverse engineering (discovering existing schemas), forward engineering (generating DDL), and synchronizing changes between the data model and the live database instance, ensuring the model remains an accurate representation of reality.
The need for real-time analytics drives the adoption of event-based and stream modeling techniques, requiring tools that can define schemas for highly de-normalized or temporal data structures suitable for high-velocity ingestion and low-latency querying.
Vendors face challenges related to the non-standardized schemas of legacy databases, poorly documented data lineage, and the requirement for complex transformation scripts during reverse engineering, often necessitating manual intervention and specialized consulting services.
Data Mesh promotes decentralized data ownership, requiring modeling tools to support domain-specific modeling while enforcing centralized policies and standards. Tools must facilitate the creation of high-quality, interoperable data products across independent teams.
Standalone tools are typically favored by mid-sized organizations, highly specialized database development teams, or consultancy firms requiring deep feature sets for specific database technologies without needing the full integration capabilities of larger, enterprise data governance suites.
While modeling unstructured data in its raw form is challenging, platforms handle it by defining schemas for metadata attached to the unstructured assets or by modeling the resulting structured data output once it has been processed and stored in a NoSQL format like a document store or key-value database.
The main value proposition is providing a clear, non-technical conceptual map of critical business entities and their relationships, enabling business analysts and decision-makers to understand data context and requirements without needing SQL or database structure knowledge.
The average adoption cycle for large-scale enterprise implementation, including tool selection, customization, integration with existing ETL/governance tools, and full training, typically spans 9 to 18 months, depending on the complexity of the data environment.
The Manufacturing sector is adopting these tools to manage complex supply chain data, optimize IoT sensor data from factory floors, and integrate operational technology (OT) data with enterprise systems, all requiring structured, high-quality data models for advanced predictive maintenance and efficiency analysis.
Subscription-based (SaaS) licensing models are rapidly increasing penetration, especially in high-growth regions like APAC and LATAM, offering lower initial costs and greater scalability compared to traditional perpetual licenses favored by established large enterprises in NA and Europe.
The On-Premise segment will see slow decline relative to Cloud, but will remain relevant due to critical security requirements in highly regulated sectors (Government, Defense, Banking) and organizations managing proprietary, sensitive data that legally or practically cannot reside on public cloud infrastructure.
Modeling tools enforce data quality and integrity by visually defining primary and foreign keys, setting constraints (not null, unique checks), defining valid data types, and ensuring referential integrity rules are accurately translated into the physical database schema (DDL).
Vendors focusing on Data Mesh enablement gain competitive advantage by offering solutions that facilitate decentralized governance, automatically generate necessary domain-specific metadata, and promote interoperability between independently managed data products.
Normalization reduces data redundancy and improves integrity by structuring data into multiple related tables (standard for transactional systems). Denormalization intentionally introduces redundancy to improve read performance for analytical workloads by combining tables.
Database simulation allows modelers to test and validate the performance and integrity of a proposed physical model before actual deployment, estimating resource usage and identifying potential bottlenecks based on anticipated data volumes and query patterns.
These sectors require robust data modeling to manage vast, complex datasets related to infrastructure, public services, and highly sensitive intelligence. They prioritize security, auditable governance, and long-term maintainability of mission-critical databases, often relying heavily on on-premise or private cloud solutions.
They manage schema drift by continuously monitoring the live database and comparing it against the approved model. Advanced features provide automated alerts and synchronization options, allowing modelers to quickly reconcile unauthorized or unexpected changes, maintaining consistency and governance.
Low-code/no-code platforms are integrating simplified modeling capabilities, making basic schema design accessible to non-specialists (citizen modelers). This expands the user base but increases the need for enterprise tools to maintain centralized governance over these decentralized modeling efforts.
This sector is critical due to the massive volume of genomics data, electronic health records (EHRs), and the need for standardized patient data models to facilitate clinical research and ensure HIPAA compliance, driving demand for specialized, secure modeling tools.
Differentiation factors include the breadth of database platform support (especially emerging NoSQL and cloud data warehouses), the level of AI-driven automation offered, the maturity of collaboration features, and the strength of integration with enterprise data governance and ETL/ELT ecosystems.
By providing a clear, documented model of the data structures, modeling software helps developers define the precise schemas for API endpoints (input and output payloads), ensuring consistency between the data retrieved/submitted and the underlying database structure.
Challenges include transitioning from traditional relational thinking to node and relationship concepts, visualizing complex, highly interconnected structures effectively, and ensuring modeling tools accurately translate conceptual models into native graph query languages (like Cypher or Gremlin).
SMEs benefit from the availability of affordable, feature-rich cloud-based SaaS tools and the increasing adoption of open-source solutions, allowing them to implement professional-grade data governance and architectural integrity without the high initial investment required by legacy enterprise software.
Research Methodology
The Market Research Update offers technology-driven solutions and its full integration in the research process to be skilled at every step. We use diverse assets to produce the best results for our clients. The success of a research project is completely reliant on the research process adopted by the company. Market Research Update assists its clients to recognize opportunities by examining the global market and offering economic insights. We are proud of our extensive coverage that encompasses the understanding of numerous major industry domains.
Market Research Update provide consistency in our research report, also we provide on the part of the analysis of forecast across a gamut of coverage geographies and coverage. The research teams carry out primary and secondary research to implement and design the data collection procedure. The research team then analyzes data about the latest trends and major issues in reference to each industry and country. This helps to determine the anticipated market-related procedures in the future. The company offers technology-driven solutions and its full incorporation in the research method to be skilled at each step.
The Company's Research Process Has the Following Advantages:
The step comprises the procurement of market-related information or data via different methodologies & sources.
This step comprises the mapping and investigation of all the information procured from the earlier step. It also includes the analysis of data differences observed across numerous data sources.
We offer highly authentic information from numerous sources. To fulfills the client’s requirement.
This step entails the placement of data points at suitable market spaces in an effort to assume possible conclusions. Analyst viewpoint and subject matter specialist based examining the form of market sizing also plays an essential role in this step.
Validation is a significant step in the procedure. Validation via an intricately designed procedure assists us to conclude data-points to be used for final calculations.


We are flexible and responsive startup research firm. We adapt as your research requires change, with cost-effectiveness and highly researched report that larger companies can't match.

Market Research Update ensure that we deliver best reports. We care about the confidential and personal information quality, safety, of reports. We use Authorize secure payment process.

We offer quality of reports within deadlines. We've worked hard to find the best ways to offer our customers results-oriented and process driven consulting services.

We concentrate on developing lasting and strong client relationship. At present, we hold numerous preferred relationships with industry leading firms that have relied on us constantly for their research requirements.

Buy reports from our executives that best suits your need and helps you stay ahead of the competition.
Our research services are custom-made especially to you and your firm in order to discover practical growth recommendations and strategies. We don't stick to a one size fits all strategy. We appreciate that your business has particular research necessities.
At Market Research Update, we are dedicated to offer the best probable recommendations and service to all our clients. You will be able to speak to experienced analyst who will be aware of your research requirements precisely.
Market Research Update is market research company that perform demand of large corporations, research agencies, and others. We offer several services that are designed mostly for Healthcare, IT, and CMFE domains, a key contribution of which is customer experience research. We also customized research reports, syndicated research reports, and consulting services.
